Text-to-SQL Translation with LLMs
2024
deep learning / nlp

"Hmm, I wonder how LLMs can be used to translate natural language instructions into SQL queries. 🤔"
Introduction
Writing SQL queries to solve analytical and business-critical questions is a common task for data analysts and data scientists. However, writing SQL queries can be challenging for those who are not familiar with SQL syntax. In this project, I aim to explore different solutions to the task of translating natural language instructions into SQL queries. Specifically, I experimented with three different approaches:
- Fine-tuning a pre-trained encoder-decoder transformer model, the T5 model.
- Training a model with the same architecture from scratch.
- Using diverse prompt engineering techniques with a large language model (LLM).
Dataset
For this project, I used a dataset consisting of natural language instructions and their corresponding SQL queries, which target the flight_database.db. The database schema, outlined in the flight_database.schema file, includes 25 tables such as "airline," "restriction," and "flight." Each table's schema details the columns, their types, and whether they are indexed.
The text-to-SQL data is divided into training, development, and held-out test sets. Each natural language instruction (in .nl files) is paired with a ground-truth SQL query (in .sql files). Here are some examples from the training set:
-
Natural Language Instruction: List all the flights that arrive at General Mitchell International from various cities.
SQL Query:
SELECT DISTINCT flight_1.flight_id FROM flight flight_1, airport airport_1, airport_service airport_service_1, city city_1 WHERE flight_1.to_airport = airport_1.airport_code AND airport_1.airport_code = 'MKE' AND flight_1.from_airport = airport_service_1.airport_code AND airport_service_1.city_code = city_1.city_code -
Natural Language Instruction: How much is a first-class ticket from Boston to San Francisco?
SQL Query:
SELECT DISTINCT fare_1.fare_id FROM fare fare_1, fare_basis fare_basis_1, flight_fare flight_fare_1, flight flight_1, airport_service airport_service_1, city city_1, airport_service airport_service_2, city city_2 WHERE fare_1.fare_basis_code = fare_basis_1.fare_basis_code AND fare_basis_1.class_type = 'FIRST' AND fare_1.fare_id = flight_fare_1.fare_id AND flight_fare_1.flight_id = flight_1.flight_id AND flight_1.from_airport = airport_service_1.airport_code AND airport_service_1.city_code = city_1.city_code AND city_1.city_name = 'BOSTON' AND flight_1.to_airport = airport_service_2.airport_code AND airport_service_2.city_code = city_2.city_code AND city_2.city_name = 'SAN FRANCISCO'
To evaluate the models, I compared the generated SQL queries with the ground-truth queries using the F1 metric to ensure they return the same database records.
Methods
Working with the T5 Architecture
I will be working with the small variant of the T5 encoder-decoder architecture (Raffel et al., 2019). The encoder will ingest natural language queries (i.e., the input sequence) while the decoder will predict the corresponding SQL queries (i.e., the output sequence). My first task will be to finetune the pretrained T5 architecture while your second task will be to train the exact same architecture from scratch (i.e., from randomly initialized weights).
For either task, I expect simply implementing data processing with the existing T5 tokenizer and varying simple hyperparameters should lead to good baseline results. During finetuning, a common design choice is to freeze part of the model parameters (i.e., only finetune a subset of the parameters).
Here are some design choices I have made to get the best-performing fine-tuned T5 model:
- Tokenization: Utilized the Hugging Face T5 tokenizer ("google-t5/t5-small") with padding and truncation enabled to ensure consistent batch processing.
- Architecture: Only the decoder's parameters were updated during fine-tuning, with the encoder's parameters frozen to preserve pre-learned contextual representations.
- Hyperparameters: Trained using a batch size of 16, across 20 epochs, with an AdamW optimizer set to a learning rate of 5e-5.
Similarly, here are the design choices I have made to train the T5 model from scratch:
- Tokenization: Used the same Hugging Face T5 tokenizer ("google-t5/t5-small") with padding and truncation enabled for uniform input and output processing.
- Hyperparameters: Configured with a batch size of 16, trained over 50 epochs, using an AdamW optimizer with a learning rate of 5e-5.
Task 3: Prompting & In-context Learning with Large Language Models
For this task, I have experimented with in-context learning (ICL) using an LLM. I used the instruction-tuned Gemma 1.1 2B model. The LLM is frozen here, and will perform the generation task while only conditioned on the text input (prompt). I need to design prompts to experiment with zero- and few-shot prompting. In the zero-shot case, I provided instructions in the prompt, but it doesn’t include examples that show the intended behaviour. In the few-shot case, I also included examples showing the intented behaviour. I have experimented with different value of k, which is the number of examples. For few-shot prompting, I also need to experiment with different ways of selecting the examples, observe how the design choice affects the performance, and how sensitive performance is to the selection of ICL examples. In the prompt, whether to also provide additional context and indications is also worth a try, for instance, about the task, the database, or details about the intended behavior.
Here is how I have designed the prompts for the zero-shot and few-shot prompting:

How to select the examples for few-shot prompting?
For selecting the examples when ( k > 0 ) in my few-shot prompting, I employed a straightforward random selection approach. This method involves choosing ( k ) distinct example pairs randomly from the training dataset. Each pair consists of a natural language instruction and its corresponding SQL query.
Evaluation
LLM Prompting
I have experimented with different value (0, 1, 3) of k in the few-shot prompting strategy to evaluate the effectiveness of the prompts in guiding the model to generate accurate SQL queries.
Besides experimenting with the number of examples, I have also conducted ablations to evaluate the impact of different components of the prompt on the model's performance. The ablations are as follows:
- Prompting Variant 3: Removed the data schema. This experiment tested the necessity of explicitly giving the model the database schema include the table names and the column names.
- Prompting Variant 4: Removed the instruction "Using valid SQL, answer the following questions for the tables provided above. Please do not generate more information other than the SQL queries." This experiment tested the necessity of explicitly guiding the model to restrict its responses to SQL queries only.
- Prompting Variant 5: Removed the markdown SQL block indicators (```sql and ```). This ablation tested whether these formatting markers impact the model's ability to correctly format SQL queries.
The results of these ablations are shown in the table below:
| System | Query EM | F1 score |
|---|---|---|
Full model (k = 0) | 0.02789 | 0.19305 |
Variant 1 (k = 0) | 0.00000 | 0.11779 |
Variant 2 (k = 3) | 0.00643 | 0.13350 |
| Variant 3 (ablating the database schema) | 0.00643 | 0.14559 |
| Variant 4 (ablating the instruction sentence) | 0.02361 | 0.17792 |
| Variant 5 (ablating the formatting markers) | 0.00643 | 0.14702 |
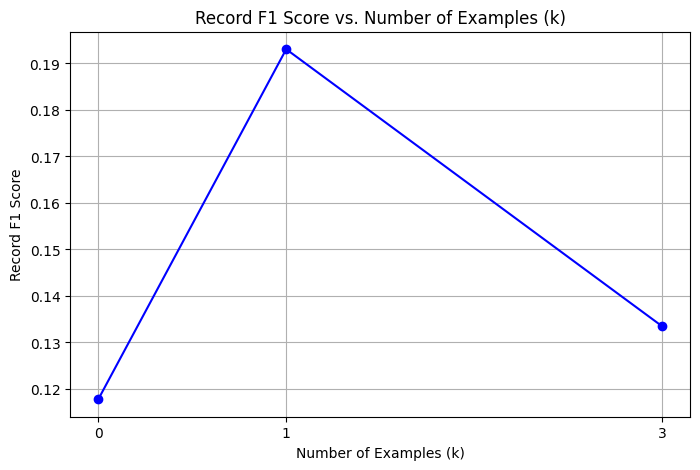
For ICL, I also visualized the Record F1 on the development set that the model achieved with different values of k.
T5 Model
The tables below shows the results of the fine-tuned T5 model and the T5 model trained from scratch:
Fine-tuned T5 model:
| System | Query EM | F1 score |
|---|---|---|
| Full model | 0.01716 | 0.62742 |
| Variant 1 (unfreeze the last layer) | 0.01502 | 0.54246 |
T5 model trained from scratch:
| System | Query EM | F1 score |
|---|---|---|
| Full model | 0.02360 | 0.57552 |
| Variant 1 (training for 20 epochs) | 0.02145 | 0.48829 |
Results on the held-out test set
The tables below show the results of the best-performing models on the held-out test set:
| System | F1 score |
|---|---|
| LLM with few-shot prompting (k = 3) | 0.15003 |
| Fine-tuned T5 model | 0.61011 |
| Trained T5 model from scratch | 0.52191 |
Qualitative Error Analysis
I have also conducted a qualitative error analysis to identify the types of errors made by the models. Here are some examples of the errors made by the models:
Un-existing Column
- Relevent Models: All models
- Example: Column
departure_airportdoes not exist:SELECT * FROM flight WHERE departure_airport = 'ORD' AND arrival_airport = 'MCI' AND flight_date = '2023-06-17' - Error Desciption: The model generates queries with columns that do not exist in the database schema.
Syntax Error
- Relevent Models: All models
- Example: One extra ")":
... WHERE flight_1.from_airport = airport_service_1.airport_code AND ... AND( flight_1.arrival_time >= 1600 ) AND( flight_1.flight_days = days_1.days_code ... - Error Desciption: Syntax errors such as unmatched parentheses disrupt the SQL query structure, leading to execution failures.
Logic Error
- Relevent Models: All models
- Example:
Natural language text: "What flights are available tomorrow from Denver to Philadelphia?"
Generated:
SELECT f.* FROM flight f JOIN flight\_stop fs ON f.to\_airport = fs.departure\_airport JOIN city c ON fs.stop\_airport = c.city\_name WHERE f.departure\_date = DATE\_ADD(NOW(), INTERVAL 1 DAY) - Error Desciption: The model fails to correctly interpret the logic of the query, such as mismatching join conditions or incorrect fields in
SELECTclause.
Conclusion
In this project, I have explored three different approaches to the task of translating natural language instructions into SQL queries. I have experimented with fine-tuning a pre-trained encoder-decoder transformer model (T5), training a model with the same architecture from scratch, and using diverse prompt engineering techniques with a large language model (LLM). The results show that the fine-tuned T5 model achieved the best performance in terms of F1 score, while the LLM with few-shot prompting also showed promising results. The qualitative error analysis revealed that the models struggled with errors such as generating queries with non-existent columns, syntax errors, and logic errors. Future work could focus on improving the models' ability to handle these types of errors, as well as exploring more sophisticated prompt engineering techniques to guide the models towards generating more accurate SQL queries.